

The Toyota Production System in the Age of Artificial Intelligence

Executive Insight | June 01, 2026
In 1896, a loom in a Japanese weaving workshop stopped itself the moment a thread snapped. The break tripped the machine, and not an inch of flawed cloth was woven. The loom was the work of Sakichi Toyoda, whose family business would later become Toyota, and the principle he built into it still carries its original name, jidoka. More than a century on, it governs how Toyota builds cars. A fault is made to show itself the instant it appears, at the exact point of failure, so the cause can be traced and fixed rather than buried in the finished product.
The same principle is at work today inside Toyota's Motomachi plant, where part-built cars drive themselves between stations, steered by sensors developed through its autonomous-vehicle work and trained to read people, machinery and obstacles around them, so that on some lines the fixed conveyor has gone altogether. In a Toyota group paint shop, AI inspection works the same way. Data from each check flows back into production, exposing the conditions that produce defects before one is ever made. The technology serves the production system, sharpening its ability to surface a fault early and trace it to its source.
How the Toyota Production System Was Built

In 1950, Eiji Toyoda, a managing director of Toyota Motor Company, travelled to the United States for three months to study American production methods. He spent six weeks at Ford, touring multiple facilities. The centrepiece was the River Rouge complex in Dearborn, the largest integrated manufacturing operation in the world. When Toyoda walked the Rouge floor, Ford was producing around 7,000 vehicles a day. Toyota, by comparison, had taken thirteen years to build its first 2,500. When he returned to Japan, his conclusion was not to copy Ford. It was that Toyota could not afford to. Ford’s model depended on scale, capital, and vast consumer markets that Toyota did not have. Japan’s post-war economy was in ruins and the domestic market was barely there. The company had just emerged from a two-month labour dispute that ended with the resignation of Eiji’s cousin Kiichiro Toyoda, then president, and the loss of roughly a quarter of its workforce.
Ford and General Motors tolerated waste, absorbed the cost through scale, and buffered against variability with inventory. Eiji Toyoda and Taiichi Ohno, a production engineer who would rise to become executive vice-president of the company, built something different. Ohno treated waste as the enemy. He designed each process to expose waste, stripped away the buffers, and surfaced problems the moment they occurred.
The idea had roots in the Toyoda family. Decades earlier, Sakichi Toyoda, Eiji’s uncle and the founder of the family’s textile business, had invented a loom that stopped itself the instant a thread broke. Build detection into the process. Halt production at the point of defect. That single idea became the foundation of what Toyota calls jidoka, one of the two structural pillars of the entire production system. The other was Just-in-Time production, which linked every step in the process to customer consumption so that nothing was made before it was needed. What Ohno built on these two pillars was a coherent system. Standardised work established the agreed method for each task and provided a stable baseline against which any deviation stood out. Visual management held the state of each process open to view across the floor, so that a fault showed itself the moment it arose rather than surfacing later in a report. Kaizen, the steady improvement carried out by the people closest to the work, turned those faults into small and lasting gains, so that the system advanced day by day.
By the late 1980s, Toyota was building vehicles with fewer defects, shorter lead times, and lower inventory than any Western manufacturer. In 2008, it overtook General Motors as the world’s largest automaker by volume, ending a 77-year GM run at the top. Thousands of organisations have studied TPS in the decades since. Few have managed to reproduce it in full. The reason most often given is the depth of cultural and operational commitment the system requires.
“The Toyota Production System is unique because it is not just a set of manufacturing techniques. It is a deeply integrated philosophy focused on creating value, eliminating waste, and continuously improving through member engagement. We build from a foundation of standardised work and good process design, which supports safety, quality, and efficiency while giving us reliable, repeatable, and capable processes. From there, we develop our members to kaizen the process and become problem solvers. TPS is a people-centric system, built on respect for people, and it assumes that no process is ever perfect and can always be improved. Its principles can be applied in any business, not just manufacturing.”

The Data That TPS Produces
TPS yields more than a better-run operation, it produces data. A system built to standardise work, remove variation, and surface deviations as they arise is, by the same design, one that captures exactly how the process behaves. What it leaves behind is a clean, continuous stream of data of the kind machine learning depends on.
Just-in-Time production synchronises material flow with customer consumption, stripping out the inventory and lead-time buffers that conceal process failures. Jidoka embeds detection into the process and halts it at the point of occurrence, so abnormalities are caught and resolved rather than passed downstream. Where conventional operations bury problems in inventory and batch-processing delays, TPS forces them into view the moment they occur, and in doing so it produces the structured data that machine learning needs.
Consider heijunka, the TPS practice of production levelling. By smoothing the swings in volume and product mix across the planning period, it removes much of the mura, the unevenness in flow, that would otherwise appear as noise in the data. The effects carry downstream as less volatility passing through the supply chain, steadier throughput, and lower work-in-progress inventory. A machine learning model learns far more from a process that is in control, where the patterns it relies on show clearly, rather than disappearing into the surrounding variation.
Jidoka, From Loom to Algorithm
Automated quality inspection is the direct descendant of jidoka, now performed with cameras and sensors rather than a mechanical trip. Sakichi Toyoda's loom carried out what would today be called binary classification at the point of occurrence, judging defect against no defect and stopping the instant the answer came back wrong. That was the 1890s. The principle is unchanged, and only the speed and precision of the tools that apply it have advanced.
What Toyoda built into the loom was subtler than automatic detection. The machine did not decide what to do about the broken thread; it stopped and called a person. Toyota gave this its own name, autonomation, automation with a human touch, and the balance it struck has become the central question of AI on the factory floor. How much should the machine resolve on its own, and where must human judgment remain? Jidoka answered that more than a century before the question was asked, holding the machine to what it does reliably, detection at the point of occurrence, and reserving judgment for the people. A modern inspection model works on the same principle. The machine is trusted to detect the defect, while the judgment on what follows stays with the people, precisely as the loom both stopped the line and left the next move to a human hand.
Lean and AI at Siemens Amberg

Amberg ranks among the most automated electronics plants in Europe, though its real strength lies beneath the automation. Decades of standardised work and process control had brought the line to a rare level of consistency.
Amberg builds the Simatic controllers used to automate factories and machinery worldwide, each one a circuit board carrying hundreds of components held in place by soldered joints. The reliability of the whole board rests on those joints, and the most critical of them sit beneath the components themselves, hidden from the optical cameras that check the rest of the board. Reaching them had always meant x-ray inspection, and as demand on that stage grew, the conventional answer was a second x-ray machine at around €500,000. The plant chose instead to train a model on the data the line already produced, identifying which boards would fail before reaching inspection.
Downstream x-ray testing fell by up to 30%, the second machine was never required, and quality held at 11 defects per million. A further x-ray stage would have deepened a bottleneck the plant had worked for years to remove, so the model spared Amberg both the capital and the constraint. Across the wider operation, the same method has cut scrap costs by roughly three-quarters, close to €3.6 million annually, and raised overall equipment effectiveness from 70% to 85%.
In a plant where every result can be traced by hand, an opaque algorithm would meet resistance, yet the operators accepted this one for speaking in the means and deviations of statistical process control, the language they had worked in for years. With that trust, the technology reached further, moving inspection from catching defects to preventing them, the purpose jidoka had always served, and restoring the continuous flow that batch testing once interrupted.
The Future Factory Operational AI Readiness Matrix
The Future Factory Operational AI Readiness Matrix locates where an operation truly stands, and in the spirit of genchi genbutsu it starts on the floor, with the work observed first-hand rather than inferred from a report. It poses two questions. The first is how far the process is in control, whether the work is governed by standardised work and held to takt time, performed the same way on every cycle at the rate the customer is buying, or still shifts from one operator and one shift to the next. The second is how far AI has been brought into the operation. Together they place an operation in one of four positions, each with its own diagnosis and its own clear next step, and across all four the principle holds, that a stable, capable process is built first and the technology is built upon it.
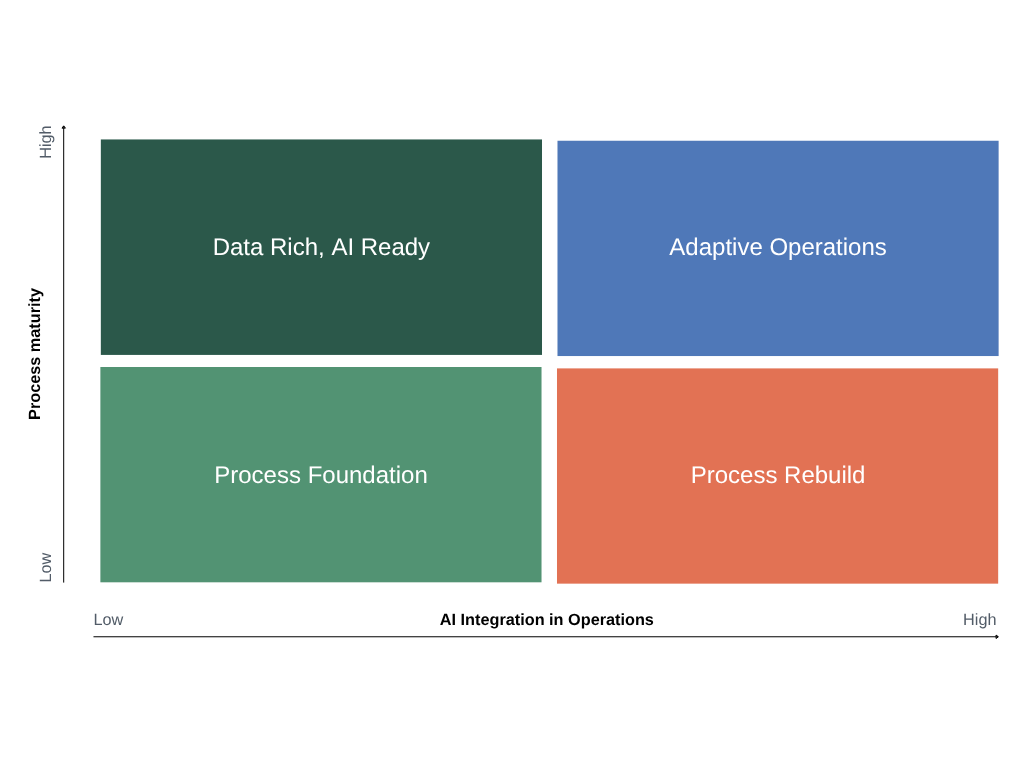
The Future Factory Operational AI Readiness Matrix
Process Foundation
This work begins on the floor, observing how the job is done, because the gap between how a process is meant to run and how it runs in practice is where the first improvement lies. This is genchi genbutsu, going to where the work happens and seeing it for yourself. Begin with value stream mapping, which traces every step a product takes from raw material to dispatch and exposes where time, effort, and value are lost. Use it to find the two or three processes that most affect your yield and on-time delivery, then work with the operators who run them to build standardised work for each, agreeing the single best method, the sequence, and the rate of customer demand the line must match. TPS calls that rate takt time. Settling it with your people rather than imposing it is what Ohno meant by respect for people, and it is why a standard the team builds for itself endures while one handed down slips quietly out of use.
Once those standards are set, the condition of the work is made visible where it happens, a practice TPS calls visual management, so that any drift from the standard is apparent to the operator at once. Detection alone is insufficient. The operator may halt the line and correct the fault at source rather than let it pass downstream, the principle of jidoka, first embodied in the self-stopping loom from which Toyota originates and seen on a modern line as a fixed stop control at the workstation.
Sustained across 90 days of plan, do, check, adjust cycles, this yields a dependable measure of performance. It also brings the first quantifiable view of mura, the unevenness always present in the process but never measured, and of the muda, the wasted effort and material, it generates. Kaizen then removes these sources of instability in turn, the largest first. What remains is a stable operation generating consistent, trustworthy data, the precondition no AI system can create for itself.
Process Rebuild
In this position the AI is already live, but the processes feeding it are not yet stable, so its accuracy gradually slips, a decline known as model drift, where a model's predictions become less reliable as the conditions around it keep shifting. Operators begin to second-guess it and step in over its outputs, and your data science team spends more of its time retraining models on fresh data than drawing any real insight from them. What works in your favour here is that the AI is already showing you where the trouble is. Each model that underperforms is pointing straight at the process feeding it, so the very system that is struggling is also telling you which process to repair first.
Stop scaling for now, and work through each live application to see which processes feed which models. Rank those processes by how much they affect your highest-value models, then go back and do the foundation work from the first quadrant. Start with genchi genbutsu, going to the floor to see the job done with your own eyes, then rebuild the standardised work and the visual management that let a problem show itself the moment it appears, the jidoka principle of building quality in at the source. Take on only two or three processes at a time, so the work stays focused rather than spread thin across the plant. Once a process steadies, a few patient cycles of PDCA, the plan, do, check, adjust loop that holds an improvement in place, will give you clean data you can trust. Retrain the model on that data and watch whether its accuracy holds instead of sliding. Accuracy that stays put is your proof that the foundation underneath it is sound, and if the model still drifts after retraining on clean data, the process is not yet stable enough, and there is more foundation work to do.
Data-Rich and AI-Ready
This is where years of process work begin to repay the effort. The standardised work is established, capability is under control, and the line now turns out clean data with each shift. The opportunity lies in asking what each TPS practice's data would let a model do, whether anticipating a failure, inspecting a joint, or forecasting demand, each of which becomes possible only once the process beneath it is sound.
The natural place to begin is the steadiest, richest seam of data, where the return is easiest to prove. A small team from process engineering, data science, and the floor can carry one model to a working pilot within a quarter, then reflect on what it taught them and move outward, model by model, from the steadiest corners of the operation toward the more variable, each step deepening the plant's capability and its trust in what the technology tells it.
Adaptive Operations
In this final position the process foundation and the AI capability reinforce one another, and the priority moves from deployment to governance. Establish formal feedback loops between your data science team and your process engineers, so that each insight an AI model produces is validated on the floor through genchi genbutsu and acted on through structured PDCA. When an anomaly detection model, the kind trained to flag data that departs from the normal pattern, surfaces a failure mode nobody had identified before, treat it as you would any other abnormality on a TPS line, investigate the root cause, update the standardised work, and close the loop. When a scheduling algorithm reveals a constraint that had been quietly shaping the flow for years, run a kaizen event to redesign around it. Built into the daily operation of the plant, this turns AI-generated insight into one more input to the same improvement cycle that already carries the insight of your people.
From there, widen the scope of autonomous decision-making, the decisions the system is trusted to make on its own, one careful step at a time. Begin with low-risk calls such as maintenance scheduling, and move to higher-stakes ones, such as the real-time pass-or-fail judgement on product quality, only once operator confidence and model reliability have been proven over repeated cycles of PDCA. Set clear boundaries for what the AI may decide independently and what still calls for human confirmation, the principle of keeping a person in the loop, and review those boundaries quarterly as the system matures. The aim throughout is a production system in which human expertise and machine capability sharpen one another with each cycle, each making the other more capable than it would be alone.
The Foundation Beneath the Smart Factory

The factory of the future is being described in terms of connected machines, continuous data, and models that adjust the line in real time. Two ideas sit at the centre of that vision. The first is the digital thread, the unbroken flow of data that follows a product across its whole life, from design through production to the floor and back, so that every stage draws on the same trusted information. The second is the digital twin, a living virtual model of a process or a machine, fed continuously by real data from the line, detailed enough to simulate a change before it is made and predict its effect. What this vision rarely states plainly is that both depend entirely on the quality of the data beneath them, and that data is a product of how the operation runs. A digital twin built on an unstable process models that instability faithfully and guides the business accordingly. This is where the Toyota Production System and artificial intelligence meet. The principles Ohno set down, standardised work, built-in quality, the steady removal of unevenness, are what produce the trustworthy data that a thread or a twin requires, and the operations that have laid that groundwork are the ones positioned to convert these technologies into durable advantage rather than expensive complexity.
The real question, then, is where the process is already sound enough to carry AI, which is a different matter from how quickly to adopt it. Be selective about where AI is deployed first, choosing the processes that have already reached stability and standardisation, and resist the pressure to scale across operations that are not yet prepared for it. Invest in the data infrastructure that captures what a stable operation produces, and invest in the people who will work alongside these systems, developing their capacity to interpret, question, and improve the tools rather than simply operate them.
TPS was built for a different era, but the principles it encodes are precisely what separates productive AI investment from costly experimentation. The factory of the future will run on the most advanced technology available to it, and it will still rest on a foundation laid down on the floor of a loom works a century ago. Build that foundation well, and the technology will follow.
SELECTED REFERENCES & FURTHER READING
E. Toyoda, Toyota: Fifty Years in Motion (Kodansha International, 1987).
K. Marr, "Toyota Passes GM as World's Largest Automaker," Washington Post, 2009.
B. Van Giffen et al., "The Culture Clash of AI Adoption in Lean Quality Management: Siemens Electronics Works Amberg," Information Systems Journal, 2025.