

Siemens Case Study: Lean Digital Factory Project

The Future Factory meets with Dr. Gunter Beitinger, Vice President of Manufacturing at Siemens, for an in-depth look at their “Lean Digital Factory” project. It will connect more than 30 plants to one Manufacturing Data Platform via MindSphere and implement a purpose-built Industrial Edge layer.
In October 2017, Siemens launched their Lean Digital Factory (LDF) program. Combining a group of experts from different business functions and technology units, its purpose is to define a conceptual holistic digital transformation roadmap for all factories of the operating company Digital Industries (DI).
To fully capture the value of using big data in manufacturing, the plants of DI needed to have a flexible data architecture which enabled different internal and external users to extract maximum value from the data ecosystem. Here, the Industrial Edge layer comes into the picture, which processes data close to the sensors and data source (figure 1).

Figure 1: The edge layer between control and cloud level (manufacturing data platform)
The Industrial Edge and data lake concept will enable a more powerful solution than any other data storage and utilisation concept:
The MDP will be a colossal storage area for all manufacturing data and will be tremendously powerful for all user levels
The MDP data platform is a centralised and indexed aggregation of distributed organised datasets
Big data will be stored in the MDP independently of its later use, this means as raw data
In combination with Industrial Edge, the MDP is the pre-requisite for effective and scalable cloud computing and machine learning
The Industrial Edge is used in this architecture for multiple purposes like data ingestion, pre-preparation, security-gate, real-time decisions.
Highly integrated, but module and service-based ecosystem functionalities.
The North Star of Lean Digital Factory and its Data

In DI, it can be challenging to harness the potential of digitalisation at full scale due to installed proprietary software solutions, customised processes, standardised interfaces and mixed technologies. However, at Siemens, this doesn’t mean that we ran a large standardisation program before leveraging the possibilities of data analytics and predictive maintenance in our plants.
To get rubber on the road at large scale, we required an architectural concept which allowed us to develop applications, scale up and transfer solutions from plant to plant, from engineering to shop floor as well as supplier to customer and reuse identified process insights from one application to another. During our LDF program, we used the “North Star” concept in combination with Reference Processes to describe exactly what we are aiming for and which functionalities we needed to benefit us in return. The “North Star” concept is very well known to lean affine people and helps to focus all implementation activities.
The linkage of the digital twin of product, production and performance will increase efficiency of our product lifecycle management process and reduce time to market. While the engineers are designing, a cost model is calculating in real time by using a design-cost relation pattern. This is mainly supported by the high maturity level and interoperability of DI Software solutions based on the PLM data backbone Teamcenter.
Another “North Star” is the full digital visualisation of the complete plant with its production lines and cells. This includes logistic processes for material and tools by “Process Simulate” and “Plant Simulation” to design and optimise all assets in the shop-floor. All data generated during the production process are collected and analysed via artificial intelligence methods to feed them back to the product and production design process for continuous optimisation.
Another example is the full automation of our planning, scheduling and sequencing of production orders to assure the best utilisation of assets during production. At the same time, we want to come as close as possible to a one-piece-flow and a takt-time which is equal to the customers takt time. One example where we use our MDP in this context, is for capacity balancing. In the DI factory network, we have a lot of electronic plants with corresponding surface mounted technology production lines. To use this synergy, we are generating a market place where we can balance the capacity across factory boundaries.
On the shop floor, autonomous guided vehicles with swarm intelligence and robot farms form a cyber physical system to organise intralogistics material supply and high flexible work arrangements. Artificial intelligence, machine learning algorithms and pattern recognition support and enable predictive maintenance, reduction of test efforts and increased machine utilisation by distributing relevant information to people via connected smart devices. In cooperation with Schmalz we implemented machine utilisation in our Amberg factory where we optimised a packaging machine using an intelligent sensor from Schmalz and Siemens software.
The data for all these scenarios must be extracted from different sources like the ERP system, “Siemens PLM system Teamcenter,” MES-level, SCADA-level, “Industrial Edge” (shop floor data), Simatic PLCs, sensors and other not yet known sources.
Knowing all the different scenarios and target states which we are aiming for, it becomes clear that traditional data warehouse architecture has its limits. The 9Vs of big data like volume, velocity, variety, veracity, value, volatility, visibility, viability and validity are now defining data. Data volume and streaming has exploded in factories due to traceability, legal regulations and quality assurance. Today, we want to analyse data from different sources: video feeds, photographs, process data, test data, log files and even text files. With this comes the challenge, which data to trust, which should be kept and which discarded? Do they need to have all the same value in units and how long is this data retained?
The Manufacturing Data Platform (MDP)

James Dixon, founder and CTO of Pentaho was the first who used the expression “Data Lake” and explained it in the following:
“If you think of a DataMart as a store of bottled water – cleansed and packaged and structured for easy consumption – the data lake is a large body of water in a more natural state. The contents of the data lake stream in from a source to fill the lake, and various users of the lake can come to examine, dive in, or take samples.”
The LDF MDP by MindSphere will enable data-driven use cases, connect and index multiple data sources via a single interface and act as a single-source of truth for the manufacturing data. The MDP provides technology, enablement, data-as-a-service and finally even analytics-as-a-service to the factories of DI and their customers:
It supports all kind of data and retains them in its raw form
Adapts to change easily (no hardware dependence) as requirements evolve
Developers and users can access all available data
App developers and data scientist can leverage existing data to create business value
Enablement of translation of business requirements to data queries and offering of final data sets to internal and external app developers and business users (data-as-a-service)
Enablement to offer deep insights and data correlations beside of raw data to internal and external app developers and business users (analytics-as-a-service)

Figure 2: The MDP eco system (target state)
Product owners and developers are supported by a “MDP-organisation” for connectivity and data sharing. Focus is on data analysis and not the technical connection. On the bottom of figure 2, we have the data sources, which can be structured and unstructured and feed into a raw data store.
Edge Computing – The New Border of the Web?
MindSphere, Manufacturing Data Platform and Industrial Edge will define the new structure of the factories for data processing. In this context, edge computing is used to optimise our cloud computing system by performing data processing at the edge of the network, which means, near to the source of the data.

Figure 3: Real time model execution on the edge and model development in the cloud
A key challenge of all our LDF use cases is, how can we get our data processed from so many different devices? Edge computing with Industrial Edge is the option, but in difference to the MDP architecture, that centralise processing and storage in a single and massive data centre, Industrial Edge pushes the data processing power to the edge devices. The main advantage is that only the results of the data processing need to be transported over networks. This provides precise and real-time results and consumes far less network bandwidth. The processing of the data is close to the source of the data.
Industrial Edge and MindSphere MDP are complementary
It makes absolute sense to divide the processing between Industrial Edge and the centralised MindSphere MDP, but one important fact has be considered. Edge computing does not store data in the long term, it eventually gets deleted, which isn't conducive for big data analytics and business models as DaaS (Data-as-a-Service) or AaaS (Analytics-as-a-Service).

Figure 4: The way from a technical infrastructure to DaaS and AaaS
If all collected data needs to be stored for cumulative analytics decision-making purposes like AI, then edge computing alone is not the right fit. This is where the MindSphere cloud based MDP has huge value, in LDF, we are creating purpose-built Industrial Edge computing-based applications in each plant in combination with the MDP where more than 30 plants will be connected. On the edge layer, there will be applications which place data processing in sensors to quickly process reactions to alarms like our spindle use case, where we predict maintenance for depanelling machines, or the algorithm-based x-ray decision which decides if a printed circuit board must be tested or not in the range of milliseconds.
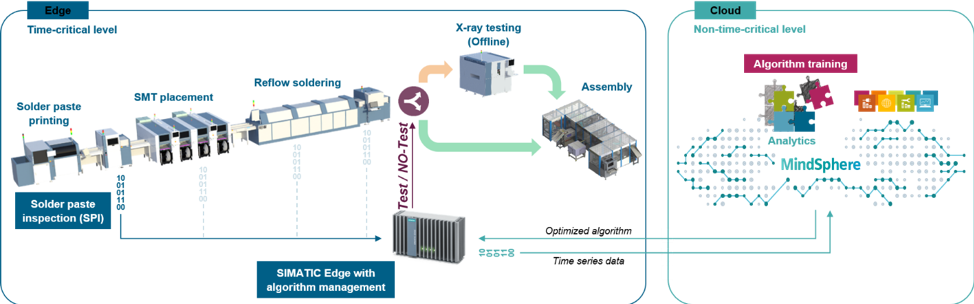
Figure 5: Architecture of the x-ray use case